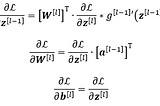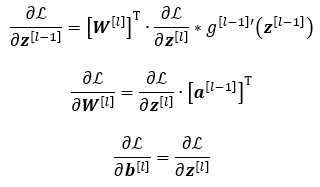Published inTDS ArchiveThe Animated Monte-Carlo Tree Search (MCTS)The algorithm at the heart of AlphaGo, AlphaGo Zero, AlphaZero and MuZeroJan 311Jan 311
Published inTDS ArchiveSpatial Transformer Networks — BackpropagationA Self-Contained IntroductionOct 12, 20211Oct 12, 20211
Published inTDS ArchiveSpatial Transformer NetworksA Self-Contained IntroductionSep 27, 2021Sep 27, 2021
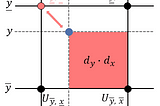
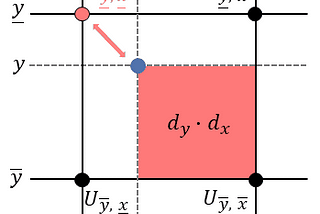
Published inTDS ArchiveSpatial Transformer Networks Tutorial, Part 2 — Bilinear InterpolationA Self-Contained IntroductionSep 13, 2021Sep 13, 2021
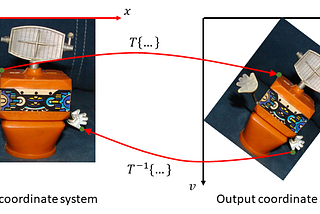
Published inTDS ArchiveSpatial Transformer Tutorial, Part 1 — Forward and Reverse MappingA Self-Contained IntroductionAug 30, 2021Aug 30, 2021
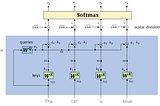
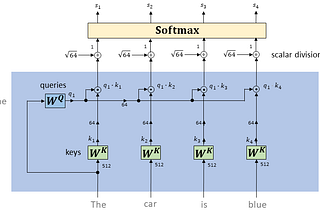
Published inTDS ArchiveTransformer Networks: A mathematical explanation why scaling the dot products leads to more stable…How a small detail can make a huge differenceApr 28, 20215Apr 28, 20215
Published inTDS ArchiveDerivative of the Softmax Function and the Categorical Cross-Entropy LossA simple and quick derivationApr 22, 202114Apr 22, 202114
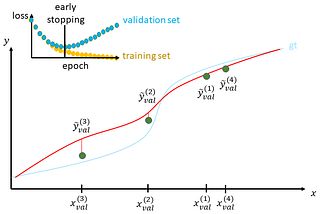
Published inTDS ArchiveAleatory Overfitting vs. Epistemic OverfittingApproaching the two reasons why your model is not able to generalize wellDec 20, 20201Dec 20, 20201
Published inTDS ArchiveDeriving the Backpropagation Equations from Scratch (Part 2)Gaining more insight into how neural networks are trainedNov 23, 20205Nov 23, 20205
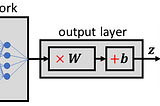
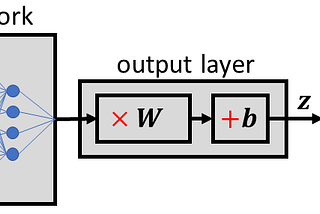
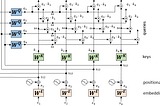
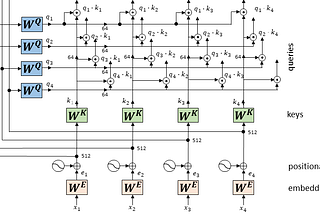
Published inTDS ArchiveDrawing the Transformer Network from Scratch (Part 1)Getting a mental model of the Transformer in a playful wayNov 15, 20207Nov 15, 20207