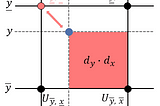
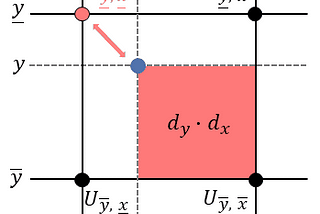
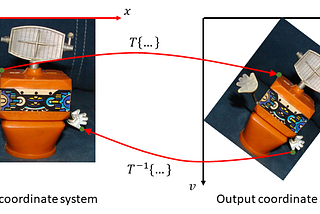
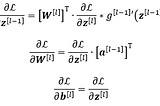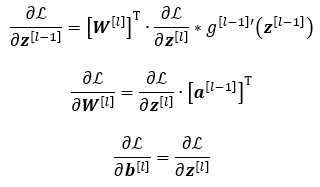Thomas KurbielinTowards Data ScienceSpatial Transformer Networks — BackpropagationA Self-Contained Introduction8 min read·Oct 12, 2021--1--1
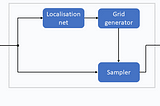
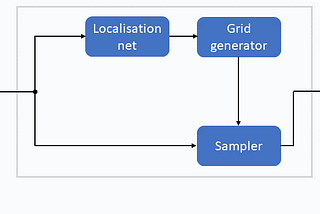
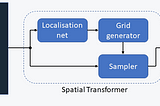
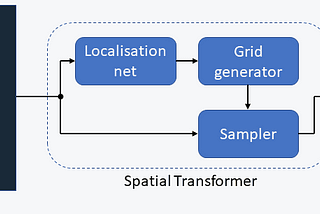
Thomas KurbielinTowards Data ScienceSpatial Transformer NetworksA Self-Contained Introduction7 min read·Sep 27, 2021----
Thomas KurbielinTowards Data ScienceSpatial Transformer Networks Tutorial, Part 2 — Bilinear InterpolationA Self-Contained Introduction6 min read·Sep 13, 2021----
Thomas KurbielinTowards Data ScienceSpatial Transformer Tutorial, Part 1 — Forward and Reverse MappingA Self-Contained Introduction6 min read·Aug 30, 2021----
Thomas KurbielinTowards Data ScienceTransformer Networks: A mathematical explanation why scaling the dot products leads to more stable…How a small detail can make a huge difference6 min read·Apr 28, 2021--5--5
Thomas KurbielinTowards Data ScienceDerivative of the Softmax Function and the Categorical Cross-Entropy LossA simple and quick derivation6 min read·Apr 22, 2021--10--10
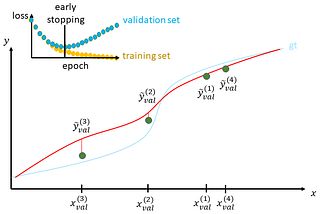
Thomas KurbielinTowards Data ScienceAleatory Overfitting vs. Epistemic OverfittingApproaching the two reasons why your model is not able to generalize well15 min read·Dec 20, 2020--1--1
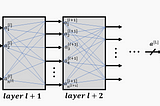
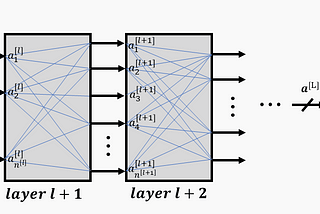
Thomas KurbielinTowards Data ScienceDeriving the Backpropagation Equations from Scratch (Part 2)Gaining more insight into how neural networks are trained6 min read·Nov 23, 2020--3--3
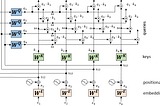
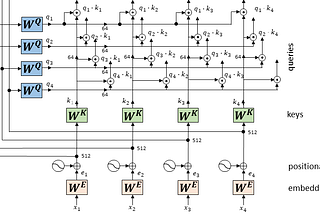
Thomas KurbielinTowards Data ScienceDrawing the Transformer Network from Scratch (Part 1)Getting a mental model of the Transformer in a playful way7 min read·Nov 15, 2020--5--5
Thomas KurbielinTowards Data ScienceDeriving the Backpropagation Equations from Scratch (Part 1)Gaining more insight into how neural networks are trained7 min read·Nov 8, 2020--2--2